Java프로젝트하면서 데이터베이스 개념 적용 및 MySQL과 연동시키기
MySQL연동하기
앞에서 구현했던 CUI프로그램은 외부파일 입출력을 통해 주소록의 데이터를 저장하고 불러올 수 있었습니다.
이제 여기서 더 나아가 관계형 데이터베이스 중 하나인 MySQL과 연동을 해보려고 합니다.
데이터베이스란 무엇인가?
데이터베이스란 어떤 조직(또는 개인)의 목표 달성 및 의사결정을 하기 위한 통합 데이터, 저장 데이터, 공유 데이터, 영속 데이터들의 집합을 뜻합니다.
데이터베이스 구성요소
1. 개체(Entity)
개체는 데이터베이스에 표현되는 대상을 뜻하는데, 필드를 멤버로 하는 레코드를 의미합니다.
개체유형(Entity type)은 추상적인 대상, 개체인스턴스(Entity Instance)는 구체적 대상으로 필드를 의미합니다.
예를 들어 주소록에서 개체유형은 name, address, telephoneNumber, emailAddresss이고, 개체인스턴스는 홍길동, 서울시 중구, 023934489, Hong@naver.com을 의미합니다.
이는 또한 속성(Attribute)이라고도 불립니다.
이 속성에는 도메인(Domain)을 지정해줘야하는데, 즉, 값의 범위를 정해줘애 합니다.
2. 도메인의 종류
도메인은 1.자료유형, 2.길이, 3.출력형식, 4.필수입력여부, 5.중복여부, 6.범위, 7.기본값, 8.유도알고리즘으로 구성됩니다.
2.1 자료유형
변수의 자료형을 설정하는 것과 같습니다. 필드에서 설정한 자료형에 따라 문자열을 설정할 수도 있고, 정수로 설정할 수도 있습니다.
2.2 길이
배열을 생성할 때 길이가 필요한 것처럼 각 속성(필드)의 최대 길이를 자료유형 옆 소괄호 안에 설정해줍니다.
2.3 출력형식
필드 중에는 출력형식이 정해진 경우가 있습니다.
예를 들어, 전화번호의 경우 02-234-5678 처럼 특정형식이 정해져있을경우 이를 설정해줍니다.
2.4 필수입력여부
필드 중에 반드시 입력을 해야 하는 부분이 있고, 아닌 부분이 있을 수 있습니다.
예를 들어, 주소록에서 이름은 필수입력 대상이지만, 이메일주소의 경우 필수입력 사항이 아닐 수 있습니다.
2.5 중복여부
필드 중에서 값이 같을 수 있는데, 예를 들어, 주소록에서 동명이인이 기재될 수 있습니다.
즉, 이름의 경우 중복이 가능하지만, 전화번호 또는 이메일 주소의 경우 중복이 있을 수 없습니다.
2.6 범위
특정 필드의 경우 범위가 존재할 수 있는데, 예를 들어 월(Month)의 경우 범위는 1~12로 설정해야 합니다.
2.7 기본값
시스템상에서 기본적으로 설정된 값을 의미합니다.
즉, 초기값을 의미합니다.
2.8 유도알고리즘
특정 필드가 원하는 형태로 되도록 설정하는 알고리즘입니다.
좀 더 자세한 것은 아래에서 설명하도록 하겠습니다.
3. 관계(Relationship)
관계에 대해서는 다음으로 진행할 프로젝트인 명함철(VisitingCardBinder)프로그램에서 MySQL과 연동할 때 좀 더 자세하게 설명하도록 하겠습니다.
데이터베이스 구조
데이터베이스의 구조로는 인간이 이해할 수 있는 논리적인 구조, 즉, 데이터베이스 설계과정이 있습니다.
또한 이 설계를 바탕으로 컴퓨터가 이해할 수 있는 물리적인 구조인 스크립형(scripting)이 있습니다.
이제 이러한 지식들을 바탕으로 주소록의 데이터베이스를 설계해보도록 하겠습니다.
데이터베이스 응용프로그래밍 설계
주소록 프로그램과 MySQL과 연동을 하기 전에 먼저 어떻게 데이터베이스를 구현할지 설계합니다.
ERD(Entity Relationship Design)을 통해 관계를 설정합니다.
주소록에서 개체유형이름(Entity Type Name)은 Personal(개인)입니다.
속성(Attribute)으로는 name(이름), address(주소), telephoneNumber(전화번호), emailAddress(이메일주소), 그리고 각각의 Personal들이 가지고 있는 코드(Primary Key)가 있습니다.
모든 속성들의 자료유형은 문자열로 설정하고, 길이는 각 속성의 특성에 맞게 최대값으로 선정해줍니다.
출력형식의 경우 나머지는 딱히 정한 것이 없고, 코드의 경우 대문자P(Personal을 가리킴) + 숫자 4자리로 규칙을 정합니다.
예를 들어, 처음 데이터베이스에 입력이 되면 ‘P0001’이 되고 다음부터는 숫자를 증가시켜서 ‘P0002’가 되는 방식입니다.
이 방식으로는 9999명의 개인만 저장할 수 있기 때문에 더 많은 객체를 저장할 필요가 있다면 처음부터 규약을 정할 때 숫자 5자리로 하는 것도 방법입니다.
필수입력여부를 정할 수 있는데 필수 입력일 경우 NOT NULL, 필수 입력이 아닐 경우 NULL로 설정하지만 주소록에서는 모든 속성들을 필수 입력하도록 설정합니다.
중복여부는 중복이 없는 경우 UNIQUE, 중복이 있는 경우는 NOT UNIQUE로 설정합니다.
범위는 나머지 속성에는 해당되지 않지만 아까 언급했듯이 코드의 경우 1~9999까지의 범위를 가집니다.
또한 나머지 속성들은 기본값이 없지만 코드의 경우 기본값은 처음 시작 코드인 ‘P0001’입니다.
유도 알고리즘의 경우 나머지 속성은 해당하지 않고, 코드의 경우 무조건 PXXXX형식으로 순차적으로 숫자가 늘어나면서 작성이 되기 때문에 이렇게 작성이 될 수 있도록 유도하는 알고리즘이 필요합니다.
주소록 데이터베이스 스크립팅(Scripting)
데이터 베이스 생성을 위해서 우선 MySQL 8.0 Command Line Client를 켜서 사용자 설정 비밀번호를 입력합니다.
저는 이미 예전에 C++로 프로그래밍을 할 때, 데이터베이스를 설정해놔서 여기서는 글로 설명하도록 하겠습니다.
이 후에 데이터 정의 언어(Data Definition Language : CREATE(생성), DROP(소멸), ALTER(변경))중에서 데이터베이스 생성을 위해 CREATE을 사용합니다.
CREATE DATABASE addressbook; 을 입력한 뒤에 데이터 제어 언어(Data Control Language)인 USE를 사용합니다.
USE addressbook;을 입력합니다.
이 후 AddressBook에 Personal 테이블을 만들기 위해 아래와 같이 커맨드 라인에 입력합니다.
CREATE TABLE Personal
(
name VARCHAR(16) NOT NULL,
address VARCHAR(128) NOT NULL,
telephoneNumber VARCHAR(16) NOT NULL,
emailAddress VARCHAR(64) NOT NULL,
code CHAR(5) NOT NULL,
CONSTRAINT PersonalPK PRIMARY KEY(code)
);
이렇게 입력해주면 MySQL에 Personal테이블이 생성됩니다.
VARCHAR은 해당크기만큼 써도 되고 그 아래로 사용해도 될 경우 사용합니다.
CHAR은 반드시 정해놓은 크기만큼 사용해야 합니다.
코드의 경우 PXXXX형식으로 반드시 5자리이기 때문에 CHAR(5)로 설정하면 됩니다.
그리고 마지막으로 code를 PRIMARY KEY로 설정합니다.
이 커맨드라인에서 데이터 조작 언어(Data Manipulation Language : INSERT(삽입), SELECT(검색, 정렬), DELETE(삭제), UPDATE(갱신))를 통해 직접 데이터를 편집할 수 있습니다.
아래에서 주소록의 예시를 들어 이 데이터 조작 언어를 사용해보겠습니다.
INSERT(삽입)
INSERT INTO Personal(code, name, address, telephoneNumber, enmailAddress)
VALUES(‘P0001’, ‘홍길동’, ‘서울시 서초구’, ‘023436789’, ‘Hong@naver,com’);
INSERT INTO Personal(name, address, telephoneNumber, enmailAddress, code)
VALUES(‘김길동’, ‘서울시 중구’, ‘023674589’, ‘Kim@naver,com’, ‘P0002’);
이렇게 입력하면 데이터베이스에 2명의 데이터가 저장됩니다.
첫번째는 code, name, address, telephoneNumber, emailAddress순으로 기재했고, 두번째는 name, address, telephoneNumber, enmailAddress, code으로 기재했습니다.
VALUES에 구체적인 값(개체인스턴스)을 입력할 때 반드시 Personal의 개체유형 순서와 맞게 입력하셔야 합니다.
SELECT(검색, 정렬)
SELECT Personal.name, Personal.address FROM Personal WHERE name=’홍길동’;
위 코드를 입력하면 주소록에서 ‘홍길동’의 이름을 가진 개인들의 이름과 주소가 검색됩니다.
SELECT Personal.* FROM Personal;
위 코드를 입력하면 주소록에 저장되어 있는 모든 개인들의 정보가 입력된 순서대로 출력됩니다.
SELECT Personal.* FROM Personal ORDER BY name ASC;
위 코드를 입력하면 주소록에 저장되어 있는 모든 개인들을 이름을 기준으로 오름차순한 순서대로 출력됩니다.
DELETE(삭제)
DELETE FROM Personal WHERE code=’P0001’;
위 코드를 입력하면 해당코드에 데이터를 삭제합니다.
UPDATE(갱신)
UPDATE Personal SET address = ‘제주시 서귀포’, telephoneNumber = ‘0715839724’ WHERE code = ‘P0002’;
위 코드를 입력하면 해당 코드에 있는 데이터의 주소와 전화번호를 스크립팅에서 적은 대로 수정합니다.
이제 이것들을 바탕으로 주소록과 MySQL을 연동시키기 위한 메소드에는 어떤 것이 있는지 알아보도록 합니다.
주소록과 MySQL을 연동하기 위한 메소드
주소록에 MySQL을 연동하기 위해 Main.java에 우선 import java.sql.*;를 합니다.
프로그램이 시작할 때 MySQL에 있는 데이터베이스를 주소록으로 가져 오기 위해 Main클래스에서 load메소드를 정의합니다.
프로그램이 종료되기 전에 주소록에 있는 Personal객체들의 정보를 MySQL로 옮기기 위해 save메소드를 정의합니다.
주소록에서 기재하기를 할 때, 기재한 정보를 MySQL에도 바로 실시간으로 추가하기 위해 insert메소드를 정의합니다.
insert 메소드는 내부에서 getCode메소드 호출을 통해 code를 얻은 다음 MySQL에 code와 함께 데이터를 insert합니다.
getCode메소드는 아까 코드 유도알고리즘을 통해 구현된 메소드로 PXXXX형식으로 순차적으로 숫자를 증가시키는 코드를 생성하여 반환하는 메소드입니다.
주소록에서 Personal객체를 삭제할 때, 이를 바로 MySQL에도 반영하기 위해 delete메소드를 정의합니다.
또한 주소록에서 Persoanl객체의 정보를 수정할 때, 이를 MySQL에 반영하기 위해 update메소드를 정의합니다.
마지막으로 주소록에서 이름을 기준으로 오름차순으로 정렬할 때(arrange메소드 호출), MySQL에 있는 데이터도 정렬하기 위해 replace라는 메소드를 정의합니다.
load 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
//데이터베이스 응용프로그래밍 시작
//load
public static void load()
{
//Personal테이블에 저장되어 있는 전체 Personal객체를 검색하는 쿼리문을 String에 저장
String sql = "SELECT Personal.name, Personal.address," +
" Personal.telephoneNumber, personal.emailAddress FROM Personal;";
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(sql))
{
//rs를 다음으로 이동시킨 다음 저장된 정보를 읽어서 정보가 없을 때까지 반복함.
while(rs.next())
{
///rs에서 각 필드의 정보를 추출하여 addressBook에 기재함.
addressBook.record(rs.getString(1), rs.getString(2),
rs.getString(3), rs.getString(4));
}
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
}
}
load 코드 설명
먼저 Main클래스의 정적 멤버로 AddressBook객체를 추가합니다.
이로써 Main클래스의 모든 메소드에서 AddressBook을 입력 받을 필요없이 바로 AddressBook객체에 접근할 수 있게 되었습니다.(현재 Main클래스의 모든 메소드가 static이기 때문에)
String sql에 저장된 쿼리문은 Personal 테이블에 있는 모든 객체를 출력하는 문장인데(SELECT ~ FROM Personal;)
조건이 name, address, telephoneNumber, emailAddress 순으로 출력(code는 제외)을 의미합니다.
Connection은 데이터베이스와 연결을 위한 클래스인데 DriveManager의 getConnection(연결문자열, DB-ID, DB-PW)메소드를 통해 Connection객체와 데이터베이스를 연동시킵니다.
Statement 클래스는 일회성 SQL 문을 데이터베이스에 보내기 위한 클래스인데, Connection객체의 createStatement()메소드를 통해 객체를 생성합니다.
ResultSet클래스는 쿼리문을 실행하고 난 결과를 저장하는 테이블형태의 클래스인데 stmt.executeQuery(sql);를 통해 sql 문장을 실행하고 그 결과를 리턴하여 ResultSet에 저장함으써 객체를 생성합니다.
참고로 쿼리문이 SELECT일 경우는 Statement객체의 executeQuery메소드를 이용하고, 그 외에는(INSERT, UPDATE, DELETE) Statement메소드의 executeUpdate메소드를 이용합니다.
이 3가지 클래스의 객체들 모두 이용을 하고 나면 프로그래머가 자원을 반납해야 하기 때문에 Try-with-resources를 통해 try()소괄호 안에서 생성했기 때문에 try-catch구문이 끝나면 자동으로 자원을 반납해줍니다.
그게 아니라면 코드가 상당히 길어지고 번거로워 집니다.
아래 코드는 만약에 Try-with-resources를 하지 않았을 경우의 코드입니다.
load코드(Try-with-resources적용X)
//데이터베이스 응용프로그래밍 시작
public void Load()
{
Connection con = null;
Statement stmt = null;
ResultSet rs = null;
String sql = "SELECT Personal.name, Personal.address,
Personal.telephoneNumber, personal.emailAddress FROM Personal;";
try
{
con = DriverManager.getConnection("jdbc:mysql://localhost:3306
/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
stmt = con.createStatement();
rs = stmt.executeQuery(sql);
while(rs.next())
{
///rs에서 각 필드의 정보를 추출하여 addressBook에 기재함.
addressBook.record(rs.getString(1), rs.getString(2),
rs.getString(3), rs.getString(4));
}
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
finally
{
//사용순서와 반대로 close함
if(rs != null)
{
try
{
rs.close();
}
catch (SQLException e)
{
e.printStackTrace();
}
}
if(stmt != null)
{
try
{
stmt.close();
}
catch (SQLException e)
{
e.printStackTrace();
}
}
if(con != null)
{
try
{
con.close();
}
catch (SQLException e)
{
e.printStackTrace();
}
}
}
}
보시다시피 finally(try-catch구문에서 공통된 사항을 처리하는 구문)에서 번거롭게 코드가 길어집니다.
그래서 Try-with-resources를 이용하여 위에서처럼 번거로운 finally코드들을 제거하도록 합니다.
ResultSet rs = stmt.executeQuery(sql);이후에 rs에는 쿼리문의 실행결과로 데이터베이스에 있는 모든 개인들의 정보를 code를 제외하고, name, address, telephoneNumber, emailAddress 순으로 테이블형식으로 가지고 있을 것입니다.
즉, 한 줄에 한 Personal의 정보를 name, address, telephoneNumber, emailAddress순으로 가지고 있다는 말입니다.
ResultSet의 객체rs의 경우 처음에는 첫 데이터가 저장되어 있는 곳의 이전 위치를 가리키고 있습니다.
그래서 next메소드를 처음 실행했을 때 비로소 첫번째 데이터를 가리키게 됩니다.
그리고 next를 통해 이동했을 때 더이상 가리키는 데이터가 없을 경우 false를 반환합니다.
while(rs.next())을 통해 rs테이블의 처음부터 데이터가 없을 때까지 반복을 돌립니다.
반복구조 내부에서는 rs의 메소드인 getString()을 통해 rs로부터 Persoanl객체의 정보인 name, address, telephoneNumber, emailAddress를 얻어서 이를 addressBook.record를 통해 기재합니다.
파일이 끝날 때까지 반복을 하기 때문에 rs에 10명의 Personal정보가 있다면 10번을 반복하면서 순차적으로 addressBook에 개인의 정보가 기재됩니다.
save 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
//save
public static void save()
{
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT Personal.code FROM Personal;");
PreparedStatement pstmt = con.prepareStatement("DELETE FROM Personal;"))
{
//DB에 있는 Personal 객체 정보들을 모두 지움.
pstmt.executeUpdate();
String sql;
//명함철의 명함개수만큼 반복한다.
for (Personal personal : addressBook.getPersonals())
{
//rs를 다음으로 이동시키고 다음데이터가 있으면
if(rs.next())
{
//DB에 명함철에서 읽은 개인정보를 추가한다.
sql = String.format("INSERT INTO Personal(code, name, address, telephoneNumber," +
" emailAddress) VALUES('%s', '%s', '%s', '%s', '%s');",
rs.getString(1), personal.getName(), personal.getAddress(),
personal.getTelephoneNumber(), personal.getEmailAddress());
pstmt.executeUpdate(sql);
}
}
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
}
}
save 코드 설명
먼저 load에서 했던 것처럼 Connection클래스의 객체를 생성하여 데이터베이스와 연동을 시킵니다.
그리고 Statement객체를 생성한 다음 ResultSet에 “SELECT Personal.code FROM Personal;”의 쿼리문 결과를 테이블 형식으로 저장합니다.
PreparedStatement은 Statement와는 다르게 생성할 때 쿼리문을 매개변수로 넣어서 생성합니다.
Statement은 쿼리문을 일회성으로 사용할 경우, 즉 미정인 상태가 없이 확정이 된 경우 주로 1회용으로 사용이 됩니다.
PreparedStatement는 쿼리문이 여러번 반복하여 사용될 경우 사용합니다.
또한 쿼리문에서 각 필드들의 구체적인 값이 미정으로 되어 있을 때 이 값을 변경하면서 사용할 수 있습니다.
즉, 반복적으로 쿼리문이 사용될 때 계속해서 사용되며, 계속해서 필드값이 바뀔 때 유용하다고 할 수 있습니다.
“DELETE FROM Personal;”을 넣어서 PreparedStatement객체를 생성하였고, try구문 내에서 executeUpdate를 실행하면 데이터베이스에 있는 개인의 정보를 모두 지웁니다.
그리고 load와 마찬가지로 Connection, Statement, ResultSet, PreparedStatement는을 try()소괄호 안에서 호출함으로써 자동으로 자원이 반납되도록 합니다.
그런데 여기사 PreparedStatement대신에 Statement객체를 여러 개 만들어서 사용하면 왜 안될까? 라는 의문이 들 수 있습니다.
그래서 PreparedStatement pstmt = con.prepareStatement(“DELETE FROM Personal;”) 대신에 Statement stmt2 = con.createStatement();로 코드를 바꾸고, pstmt.executeUpdate(); 대신에 stmt2.executeUpdate(sql2);로 코드를 바꿔봤습니다.
이 후 프로그램을 실행시켜보니 에러가 발생했습니다.
그 이유는 다음과 같습니다.
아까 앞에서 Statement객체를 생성한 다음 ResultSet에 “SELECT Personal.code FROM Personal;”의 쿼리문 결과를 테이블 형식으로 저장했습니다.
그러나 뒤에서 Statement stmt2 = con.createStatement();을 통하여 다른 Statement객체를 생성하는 순간 앞에서 생성한 rs의 정보가 초기화되어버립니다.
rs의 정보가 초기화되어 정보가 없으니 당연히 rs.next();를 할 때 에러가 발생하여 프로그램이 종료됩니다.
즉, Statement는 객체의 개수와는 상관없이 한 쿼리문에 한 번 이용할 수 있습니다.
여기서는 이미 ResultSet에 쿼리문의 결과를 저장하기 위해 사용했기 때문에 더이상 ResultSet의 데이터가 필요없을 때까지는 새로운 Statement객체를 생성하여 이용하면 안됩니다.
만약에 ResultSet의 데이터를 다 사용한 다음에 더이상 쓸 일이 없다면 Statement객체를 새로 생성하여도 아무 문제는 없습니다.
그러나 이런 것이 번거롭다면 그냥 PreparedStatement를 생성하여 사용하면 됩니다.
PreparedStatement는 여러번 재사용이 가능하기 때문에 필요할 때마다 객체를 생성해주거나, 객체를 따로 생성하지 않더라도 하나의 객체를 이용하여, executeUpdate 또는 executeQuery를 할 때 그 매개변수로 자신이 원하는 sql문을 보내주면 데이터베이스에 해당 sql문을 보낼 수 있습니다.
(추가 설명 첨부:
PreparedStatement의 경우 처음에 Connection객체가 생성되고 나면 prepareStatement(쿼리문이 매개변수)생성자를 통해 쿼리문만 있다면 원하는 개수대로 PreparedStatement객체를 생성할 수 있습니다.
그러나 Statement객체의 경우 Connection객체가 생성되고 나서 createStatement(매개변수없음)메소드를 통해 한번만 생성됩니다.
이후에 Connection 객체가 그대로인데 다시 createStatement(매개변수없음)메소드를 통해 새로운 Statement객체를 생성하면 기존의 객체가 소멸되면서 이 때 기존객체로 만들어둔 ResultSet이 있다면 이 정보 역시 날라가버립니다.
그래서 Statement객체의 executeQuery(sql) 통해 SELECT쿼리문으로 ResultSet에 정보를 저장해놓았다면 다른 쿼리문을 이용하려고 할 때(비록 이게 ?가 없는 확정된 커리문이라 하더라도, ResultSet에 저장한 정보를 날리고 싶지 않다면) 새로운 Statement객체를 생성하지 말고!, PreparedStatement객체를 생성하여 다른 쿼리문을 처리해주도록 해야 합니다.
물론 이 경우 예외는 있는데 ResultSet에 정보를 먼저 이용한 다음에 더이상 ResultSet에 정보가 필요없는 경우에는 Statement객체를 다시 생성할 필요없이 기존 Statement객체로 executeUpdate(sql2)를 실행할 수 있습니다.
executeUpdate가 실행되는 순간 executeQuery로 생성된 ResultSet은 더이상 못쓰게 되지만 이미 다 사용했기 때문에 더이상 필요가 없을 경우라면 괜찮습니다.
)
다시 코드로 돌아가서 pstmt.executeUpdate();를 통해 데이터베이스에 있는 모든 개인정보를 지웁니다.
그 전에 ResultSet rs = stmt.executeQuery(sql);를 통해 데이터베이스에서 개인코드 정보는 ResultSet에 저장해놨습니다.
for each 반복구조 안에서 rs.next를 호출합니다.
ResultSet의 경우 처음에는 자신의 첫번째 데이터보다 이전에 위치하고 있습니다.
그래서 rs.next를 하면 그제서야 비로소 자신의 첫번째 데이터를 가리키게 됩니다.
그리고 rs.next를 통해 파일의 마지막 이후에 rs가 위치하게 되면, 즉, ResultSet객체에 데이터가 더이상 없을 경우 false를 반환합니다.
물론 처음부터 데이터가 없어도 rs.next는 false를 반환합니다.
그리고 데이터가 있을 때에는 true를 반환합니다.
그러나 이때 유의할 점이 rs.next는 실제로 ResultSet의 데이터를 다음으로 이동시킨 다음에 그 결과 데이터가 있으면 true를 반환하고, 없으면 false를 반환한다는 점입니다.
즉, 선택구조를 통해 if(rs.next() == true)이렇게 물어보는 순간에 이미 rs는 다음으로 이동을 한다는 것입니다.
현재 ResultSet에는 데이터베이스로부터 전체 개인의 코드정보가 테이블형식으로 저장되어 있습니다.
그래서 차후에 이 개인코드를 추출하기 위해 rs.getString(1);을 사용할 것인데 만약 rs에 데이터가 없다면 에러가 발생하기 때문에 선택구조를 통해 rs.next를 이동시키고, true이면(데이터가 있는 경우에만) 선택구조를 들어가서 rs.getString(1);을 호출합니다.
“INSERT INTO Personal(code, name, address, telephoneNumber, emailAddress) VALUES(‘%s’, ‘%s’, ‘%s’, ‘%s’, ‘%s’);” 의 쿼리문에서 처음 code에 rs.getString(1);을 통해 추출한 코드 정보를 매개변수로 넣어줍니다.
getString의 경우 ResultSet에 저장된 데이터를 번호에 맞게 추출합니다.
예를 들어 ResultSet에 “SELECT Personal.code, Personal.name FROM Personal;”쿼리문으로 데이터가 저장되어 있다면 ResultSet은 전체 개인의 코드와 성명 데이터를 저장하고 있을 것입니다.
여기서 getString(1)을 하면 code정보, getString(2)를 하면 name정보를 추출할 것입니다.
다시 코드로 돌아가서 코드 이외에 나머지 정보는 for each반복문을 통해 구한 Personal객체의 getter메소드를 통해 완성된 INSERT 쿼리문을 만든 다음 pstmt.executeUpdate(sql); 통해서 데이터베이스에 해당 개인의 정보를 추가해줍니다.
PreparedStatement의 객체인 pstmt의 경우 생성시에는 “DELETE FROM Personal;”쿼리문을 통해 생성되었지만 이렇게 executeUpdate메소드에 다른 쿼리문을 매개변수로 넣고 실행해주면 매개변수로 넣은 쿼리문을 데이터베이스에 전달합니다.
그래서 PreparedStatement가 Statement보다 재활용성이 훨씬 뛰어납니다.
getCode 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
//getCode
public static String getCode()
{
String code = "P0000";
String newCode = null;
String sql = "SELECT Personal.code FROM Personal;";
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
// Statement 객체 생성 및 move를 단방향이 아닌 자유롭게 할 수 있도록 하기 위한 조치
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE);
ResultSet rs = stmt.executeQuery(sql))
{
//마지막이 이동 후에 마지막에 데이터가 있으면
if(rs.last())
{
code = rs.getString(1);//마지막코드를 읽어들임
}
//코드에서 숫자부분만 추출함
code = code.substring(1,5);
//코드에서 추출한 숫자부분 문자열을 정수형으로 바꿔줌
int number = Integer.parseInt(code);
//정수형으로 바꾼 코드를 +1해줌
number++;
//+1이 된 새로운 개인코드를 생성함.
newCode = String.format("P%04d", number);
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
//새로 생성한 코드를 반환한다.
return newCode;
}
}
getCode 코드 설명
먼저 위에서 봤던 메소드들과의 차이점으로 Statement 객체 생성 시 ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE를 매개변수로 입력한 것을 볼 수 있습니다.
Statement 객체 생성 시 매개변수없이 createStatement()를 통해 Statement객체를 생성하면 디폴트값이 ResultSet.TYPE_FORWARD_ONLY으로 설정됩니다.
ResultSet.TYPE_FORWARD_ONLY일 경우 ResultSet객체에서 이동할 때 오직 다음 방향 한 행으로만 이동할 수 있습니다.
이때까지 load나 save의 경우 rs.next를 사용하여 다음으로만 이동하였기 때문에 디폴트값이 ResultSet.TYPE_FORWARD_ONLY어도 아무 문제가 없었습니다.
그러나 getCode에서는 ResultSet을 바로 마지막으로 이동시켜야 하는데(last메소드를 통해) 이 경우 디폴트값이 ResultSet.TYPE_FORWARD_ONLY이면 바로 에러가 납니다.
그래서 ResultSet.TYPE_SCROLL_SENSITIVE을 매개변수로 입력함으로써 RecordSet이 last로 바로 자유롭게 이동할 수 있고, 데이터 변경이 바로 적용될 수 있도록 합니다.
그리고 첫번째 매개변수를 입력하면 다음 매개변수도 필수적으로 입력을 해야 하는데 두 번째 매개변수로 올 수 있는 것이 ResultSet.CONCUR_READ_ONLY(데이터를 읽을 수만 있음)과 ResultSet.CONCUR_UPDATABLE(데이터를 수정할 수 있음)이 있습니다.
둘 중에 아무거나 해도 상관은 없지만 데이터를 바꿀수도 있고, 꼭 바꾸지 않아야 할 이유가 없어서 저는 ResultSet.CONCUR_UPDATABLE를 선택했으나 READ_ONLY를 해도 딱히 상관은 없어 보입니다.
아무튼 적절한 매개변수를 입력하여 Statement객체를 생성하였고, 이 Statement객체를 통해서 sql(SELECT쿼리문)을 실행할 결과(데이터 베이스에 저장된 전체코드데이터)가 ResultSet에 저장되었습니다.
여기서 다음 코드를 설명하기 전에 제가 처음으로 구현한 잘못된 코드를 먼저 보면서 잘못된 결과를 보도록 하겠습니다.
getCode 잘못된 코드
//getCode
public static String getCode()
{
String sql = "SELECT Personal.code FROM Personal;";
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
//Statement 객체 생성 및 move를 단방향이 아닌 자유롭게 할 수 있도록 하기 위한 조치
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,
ResultSet.CONCUR_UPDATABLE);
ResultSet rs = stmt.executeQuery(sql);)
{
rs.last();
//resultSet에 저장된 Personal객체의 수를 구한다.
int number = rs.getRow();
number++;
String code = String.format("P%04d", number);
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
return code;
}
getCode 잘못된 코드 설명
전자(올바른 코드)와 후자(잘못된 코드)의 차이는 try{}안에서의 처리과정입니다.
후자의 경우 간편하게 ResultSet의 마지막으로 이동한 뒤에 getRow를 통해 행의 개수를 구하면 마지막 Personal객체까지의 수(number)를 구할 수 있습니다.
insert에서 getCode를 사용하여 code를 생성하는데, insert의 경우 순차적으로 마지막 Personal객체 다음에 추가하기 때문에 여기서도 마지막 number에서 +1을 하여 그 number를 토대로 코드를 생성하면 될 것이라고 착각(?)을 하게 되었습니다.
잘못된 이유 : 종합적 사고력의 부재
이렇게 단순하게 코드를 짜면 당장에 기재하기를 할 때는 아무 문제없이 돌아갑니다.
그러나 나중에 delete를 하게 되면 문제가 발생하게 됩니다.
code의 경우 Primary KEY값으로 UNIQUE하기 때문에 중복이 있을 수 없습니다.
그런데 예를 들어 비어 있는 데이터베이스와 연동되어 있는 주소록에 10명을 순차적으로 record했다고 가정합시다.
그럼 이제 데이터베이스에는 10명의 개인의 정보가 저장되어 있고, 마지막으로 추가된 개인의 코드 번호는 현재 “P0010”일 것입니다.
이 때 주소록에서 다섯번째로 기입된 개인을 erase하면 데이터베이스에서는 “P0005”코드의 개인을 데이터에서 지울 것입니다.
이후에 새로운 개인을 주소록에 record할 때 이 개인은 몇 번째 코드를 받아야할까요?
아까 말했듯이 code는 한번 설정되면 바뀌지 않고 UNIQUE하기 때문에 새로 추가된 개인은 “P0011”코드를 받아야 합니다.
그리고 아까 지워졌던 “P0005”은 계속 비워져있을 것입니다.
그런데 위의 코드에서는 이것을 반영하지 않고, 무조건 마지막으로 이동한 다음(rs.last())에 그 개수를 세고(rs.getRow()) 있습니다.
그렇게 되면 아까와 같은 상황에서 10명의 개인이 있을 때 1명이 지워지면 9명으로 줄어들게 되지만 마지막 개인의 코드는 여전히 “P0010”입니다.
이 때 새로운 개인을 추가하면 위의 코드대로(rs.last()->rs.getRow())현재 9명이기 때문에 코드는 9명에 + 1을 하여 “P0010”코드가 생성됩니다.
그렇게 되면 UNIQUE한 코드가 중복되어 데이테베이스에 오류가 발생하게 됩니다;;
올바른 코드 다시 설명(+종합적 사고력이 필요함)
이를 바로 잡기 위해 우선 String code = “P0000”;으로 초기화를 합니다.
이 후 try구문 내에서 if(rs.last())를 통해 마지막으로 이동한 다음에 마지막 데이터가 있으면 마지막 코드를 쿼리문에서 읽습니다.(code = rs.getString(1);)
현재 쿼리문은 전체 Personal테이블의 코드만 저장하고 있기 때문에 getString(1)을 통해 마지막 Personal객체의 코드를 얻을 수 있습니다.
이렇게 선택구조를 한 이유는 처음 입력될 경우, 즉, 데이터베이스에 아무 데이터도 저장이 되어 있지 않은 경우에는 가져올 코드가 없기 때문에 에러가 발생하는데 이를 방지하기 위해 최소 1개이상의 데이터가 있을 경우에만 선택구조로 들어가서 마지막 코드를 가져올 수 있도록 하였습니다.
code = code.substring(1,5);를 통해 P를 제외하고 숫자 4자리만 문자열로 얻어옵니다.
선택구조로 들어갔다 나왔으면 마지막 코드 4자리가 있을 것이고, 기존 데이터없이 처음 입력하는거라 선택구조를 들어가지 않았다면 0000이 code에 저장될 것입니다.
number = Integer.parseInt(code);를 통해 숫자로 변경시켜줍니다.
그리고 +1(number++;)을 합니다.
숫자로 변경될 때 앞의 0들은 사라지기 때문에 String으로 다시 변경할 때는 P%04d를 통해 앞에 없앴던 P를 다시 붙여주고, 0도 다시 채워줍니다.
예를 들어 마지막으로 코드가 10이였으면 +1을 하여 11이 되고, 이를 위의 방식대로 문자열로 바꿔주면 “P0011”이 됩니다.
이처럼 어떠한 메소드를 구현할 때 하나의 메소드만 두고 봤을 때 제대로 돌아간다고 박수를 치면 안됩니다.
프로그램이 복잡해질수록 하나의 메소드가 다른 여러 메소드와 관련이 있기 때문에 이 연관성을 고려하여 코드를 설계할 수 있는 종합적인 사고력이 필수라고 생각합니다.
이제 이 완성된(중복이 없는)코드를 반환하면 insert에서 이 코드를 이용하여 데이터베이스에 새로운 Personal객체 정보를 추가합니다.
또다른 방식의 getCode
//getCode
public static String getCode()
{
String code = "P0000";
String newCode = null;
//내림차순으로 개인코드 정렬하기
String sql = "SELECT Personal.code FROM Personal ORDER BY code DESC;";
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(sql))
{
//데이터가 있으면
if(rs.next())
{
code = rs.getString(1);//마지막코드를 읽어들임
}
code = code.substring(1,5);
int number = Integer.parseInt(code);
number++;
newCode = String.format("P%04d", number);
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
return newCode;
}
또다른 방식의 getCode설명
이전의 getCode와 거의 비슷하긴 한데 처음에 Statement클래스 객체로 실행할 쿼리문(“SELECT Personal.code FROM Personal;”;)의 마지막에 ORDER BY code DESC;”;를 덧붙입니다.
이렇게 되면 코드번호가 높은 순대로 내림차순으로 정렬되기 때문에 ResultSet의 제일 첫번째 데이터가 제일 높은 코드번호를 가지게 됩니다.
그러면 Statement객체를 생성할 때 매개변수없이 빈칸으로 디폴트생성자를 이용하면 됩니다.
그리고 rs.last()대신 rs.next()를 이용하여 처음 데이터로 이동하면 내림차순이기 때문에 바로 마지막 데이터 정보를 얻을 수 있습니다.
그 이외에는 예전 방식과 같습니다.
insert 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
public static void insert(int index)
{
String sql = "INSERT INTO Personal(code, name, address,
telephoneNumber, emailAddress)" +
" VALUES(?, ?, ?, ?, ?);";
try(Connection con = DriverManager.getConnection("jdbc:mysql:" +
"//localhost:3306/AddressBook?serverTimezone=Asia/Seoul",
"root", "1q2w3e");
PreparedStatement pstmt = con.prepareStatement(sql);)
{
Personal personal = addressBook.getAt(index);
String code = getCode();//getCode로 새로운 code생성
pstmt.setString(1, code);
pstmt.setString(2, personal.getName());
pstmt.setString(3, personal.getAddress());
pstmt.setString(4, personal.getTelephoneNumber());
pstmt.setString(5, personal.getEmailAddress());
//PreParedStatement 객체 생성, 객체 생성시 SQL 문장 저장
pstmt.executeUpdate();
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
}
}
insert 코드 설명
sql문은 아까 스크립팅할 때 새로운 개인의 데이터를 데이터베이스에 추가할 때 사용한 것과 같습니다.
차이점이라고는 뒤에 구체적인 사항들(개체인스턴스)가 “?”로 아직 미정이라는 점입니다.
이 sql쿼리문으로 PreparedStatement객체를 생성합니다.
insert호출 시에 매개변수로 입력받는 index는 아래의 코드처럼 addressBook에서 record한 후에 반환 받는 index(최근에 추가한 개인의 배열위치)인데 이를 매개변수로 이용하여 addressBook에서 personal의 정보를 얻어옵니다.
int index = addressBook.record(name, address, telephoneNumber, emailAddress);
insert(index);
그런 다음 getCode를 호출해 새로운 code를 생성한 후에 이를 반환받습니다.
새로 생성한 code와 주소록에 새로 추가한 개인의 정보를 PreparedStatement의 setString메소드를 통해 순차적으로 아까 “?”로 비워져있던 항목들을 sql쿼리문에 채워넣습니다.
그 다음 executeUpdate를 호출하면 데이터베이스에 새로운 개인의 데이터가 저장됩니다.
update 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
public static void update(int index)
{
//데이터베이스에 있는 전체 개인들의 코드를 순차적으로 저장함.
String sql = "SELECT Personal.code FROM Personal;";
try(Connection con = DriverManager.getConnection("jdbc:mysql:" +
"//localhost:3306/AddressBook?serverTimezone=Asia/Seoul",
"root", "1q2w3e");
PreparedStatement pstmt = con.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();)
{
//매개변수로 입력 받은 위치의 개인을 구함.
Personal personal = addressBook.getAt(index);
String code = null;
int i= 0;
//매개변수로 입력 받은 위치만큼 반복하면서 개인코드로 이동함.
while(i <= index)
{
//rs를 다음으로 이동시키고 다음이 있으면
if(rs.next())
{
//개인 코드를 구한다.
code = rs.getString(1);
}
i++;
}
//데이터베이스에서 개인코드에 해당하는 정보를 수정한다.
sql = String.format("UPDATE Personal SET address='%s'," +
" telephoneNumber='%s', emailAddress='%s'" +
" WHERE code='%s';",
personal.getAddress(), personal.getTelephoneNumber(),
personal.getEmailAddress(), code);
pstmt.executeUpdate(sql);
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
}
}
update 코드 설명
위의 sql문은 데이터베이스에서 전체 개인코드를 구하는 구문입니다.
이 sql문으로 PreparedStatement를 생성하여 executeQuery를 통해 ResultSet객체(전체코드를 테이블형식으로 저장)를 생성합니다.
update호출 시에 매개변수로 입력받는 index는 addressBook에서 correct한 후에 반환 받는 index(주소록에서 내용을 변경한 개인 배열위치)인데 이를 매개변수로 이용하여 addressBook에서 personal의 정보를 얻어옵니다.
index = addressBook.correct(indexes.get(index), address, telephoneNumber, emailAddress);
update(index);
while(i <= index)
을 통해 입력받은 index까지 반복을 돌리면서 rs에서 index와 일치하는 개인의 코드로 이동합니다.
반복구조 내부에서는 rs.next();를 통해 rs를 이동시키면서 다음데이터가 있으면 code = rs.getString(1);(코드 데이터 하나만 저장되어 있음.)를 통해 code를 얻어옵니다.
이 반복구조를 벗어날 때 code에는 주소록 index와 일치하는 개인의 code가 저장되어 있습니다.
왜냐하면 주소록과 데이터베이스의 저장 순서가 동일하기 때문에 주소록의 index만큼 반복을 돌리면서 rs가 순차적으로 이동하면 index에 도착했을 때 code를 가지는 개인은 주소록과 동일할 수밖에 없기 때문입니다.
이렇게 code를 얻고 나면 String.format으로 새로운 쿼리문(변경)을 만들어 준 다음에 이를 실행(pstmt.executeUpdate(sql))합니다.
그러면 데이터베이스에도 성공적으로 해당 코드의 개인 데이터 변경이 이루어지게 됩니다.
delete 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
public static void delete(int index)
{
String sql = "SELECT Personal.code FROM Personal;";
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(sql);)
{
String code = null;
int i= 0;
while(i <= index)
{
//rs를 다음으로 이동시키고 다음이 있으면
if(rs.next())
{
//개인 코드를 구한다.
code = rs.getString(1);
}
i++;
}
sql = String.format("DELETE FROM Personal WHERE code = '%s';", code);
stmt.executeUpdate(sql);
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
}
}
delete 코드 설명
delete 코드의 원리는 update 코드와 동일합니다.
sql문은 update와 동일하게 전체 코드를 출력하는 문장입니다.
delete에서도 PreparedStatement를 써도 되지만 여기서는 Statement를 쓰도록 하겠습니다.
Statement를 여기서 써도 되는 이유는 앞에서 언급했듯이 Statement를 이용하여 생성한 ResultSet을 먼저 다 이용하고, 더이상 필요없을 때 executeUpdate를 하는데, 이 때는 ResultSet이 더이상 필요없어서 닫혀도 문제가 없기 때문입니다.
delete호출 시에 매개변수로 입력받는 index는 addressBook에서 erase한 후에 이 반환값을 이용하지 않고, erase의 매개변수로 사용했던 값을 그대로 매개변수로 사용합니다.
addressBook.erase(indexes.get(index));
delete(indexes.get(index));
이 index(주소록에서 지울 개인 배열위치)를 매개변수로 이용하여 반복구조에서 이용합니다.
주소록에서는 이미 index에 해당하는 개인이 지워졌지만,
아직 데이터베이스에서는 해당하는 개인이 남아있기 때문에 while(i <= index) 반복구조(내부에서 ResultSet의 이동)를 통해 데이터베이스에서 해당하는 개인(주소록에서 지워진 개인)의 코드를 알아낼 수 있습니다.
그리고 이렇게 알아낸 개인의 코드를 이용하여 새롭게 만든 삭제 쿼리문을 실행시킴으로써 데이터베이스에서 주소록에서 지운 개인과 동일한 개인을 지울 수 있습니다.
repalce 코드
public class Main
{
//정적 멤버로 AddressBook객체를 추가함.
private static AddressBook addressBook;
public static void replace()
{
try(Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306" +
"/AddressBook?serverTimezone=Asia/Seoul", "root", "1q2w3e");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT Personal.code FROM Personal;");
PreparedStatement pstmt = con.prepareStatement("DELETE FROM Personal;"))
{
//DB에 있는 Personal 객체 정보들을 모두 지움.
pstmt.executeUpdate();
String sql;
//명함철의 명함개수만큼 반복한다.
for (Personal personal : addressBook.getPersonals())
{
//rs를 다음으로 이동시키고 다음데이터가 있으면
if(rs.next())
{
//DB에 명함철에서 읽은 개인정보를 추가한다.
sql = String.format("INSERT INTO Personal(code, name, address, telephoneNumber," +
" emailAddress) VALUES('%s', '%s', '%s', '%s', '%s');",
rs.getString(1), personal.getName(), personal.getAddress(),
personal.getTelephoneNumber(), personal.getEmailAddress());
pstmt.executeUpdate(sql);
}
}
}
catch (SQLException e)
{
System.out.println("[SQL Error : " + e.getMessage() +"]");
}
}
}
replace 코드 설명
코드를 보시면 어디서 많이 본 것 같은 느낌을 받으실 겁니다.
정확합니다.
이 코드는 save와 완벽하게 일치합니다.
그럼 그냥 save를 쓰면 되지 왜 replace라고 별도로 명칭을 지었냐고 물으신다면, arrange에서 save를 호출하는 것은 명칭상 맞지 않다고 생각하여 새로 replace를 만들었습니다.
그래서 프로그램이 종료될 때는 save라는 메소드를 이용하고, 정렬할 때는 replace라는 메소드를 이용하도록 했습니다.
솔직히 replace는 단어 그대로 기존에 데이터를 대체시킨다는 뜻입니다.
replace의 호출 시점은 addressBook의 arrange가 호출 된 바로 직후입니다.
addressBook.arrange();
replace();
arrange호출 후에 replace가 호출되면 어떻게 될까요?
일단 전체 데이터의 코드만 ResultSet에 저장하고 데이터베이스의 모든 Personal데이터를 지웁니다.
그리고 이제 데이터베이스에는 이름 기준으로 오름차순으로 정렬된 AddressBook의 개인들이 순차적으로 insert되는데 이때 code역시 순차적으로 부여받으면서 데이터베이스에 저장됩니다.
이게 뭐가 문제일까요?
아까 언급드렸듯이 데이터베이스에서 code는 primaryKey라서 한번 객체에 부여되면 변경이 불가하다고 말했습니다.
근데 주소록에서 아무도 추가한 것도 없고, 지운것도 없이 정렬만 했을 뿐인데 모든 개인들의 code들이 전부 변경이 되는 사태가 발생합니다.
예를 들어, 홍길동은 제일 먼저 기재되어 code가 “P0001”이었고, 김길동은 제일 최근에 기재되어 code가 “P0010”이었는데 정렬하기를 마치고 나면
(홍길동이 오름차순으로 제일 마지막이고 김길동이 제일 처음이라는 가정하에), 김길동의 code는 “P0001”이 되고, 홍길동의 코드는 “P0010”이 됩니다;;
개념상 code는 바뀌면 안되는데 code가 완전히 바껴버리는 어이없는 사태가 벌어지고 맙니다.
그래서 정렬을 하더라도 code는 손대지 않는 쪽으로 바꾸려는 시도를 했습니다.
즉, code는 그대로 두고 정렬만 시키는 방법을 생각해봤습니다.
대안책
방법은 전체 code를 저장하는 쿼리문 “SELECT Personal.code FROM Personal;”을 SELECT Personal.code FROM Personal ORDER BY name ASC;으로 바꿔줍니다.
그러면 이름기준으로 오름차순으로 code가 저장될 것입니다.
이후에 데이터베이스를 전체 지웁니다.
그리고 addressBook.arrange를 한 후에 repalce메소드를 호출하면 이름기준으로 오름차순으로 된 상태의 개인들을 데이터베이스에 다시 넣습니다.
그렇게 되면 개인들은 순서만 바뀌고, 원래 코드는 그대로 가지게 됩니다.
예를 들어, 아까 “홍길동”의 경우 제일 처음 입력되어 코드가 “P0001”이었고, “김길동”의 경우 제일 마지막에 입력되어 코드가 “P0010”이었습니다.
이 방법으로 replace되고 나면 데이터베이스에서 “홍길동”의 경우 제일 마지막인 10번째로 밀려나지만 코드는 여전히 “P0001”입니다.
“김길동”의 경우 첫번째로 이동하지만 코드는 “P0001”이 됩니다.
자 이제 모든 것이 해결된 것처럼 보이는 해피엔딩인 줄 알았습니다.
그리고 프로그램을 여러 번 작동시켜 보았습니다.
생각하지 못한 문제가 발생했습니다.
대안책의 문제점
대안책의 방법대로 하면 정렬을 할 때 마다 데이터베이스에서는 code순서가 뒤죽박죽이 됩니다.
원래 처음에 데이터베이스에 입력될 때는 code는 기입된 순서대로 순차적으로 증가하는 방식이었습니다.
근데 대안책을 사용하고 나면 더이상 code순서와 입력순서가 동일해지지 않습니다.
여기서 엄청난 문제가 발생하게 됩니다;;
지금까지 앞에서 구현했던 메소드들은 모두 code는 입력 순서에 맞게 순차적으로 증가한다는 가정 하에 로직을 세웠습니다.
근데 이 기본 가정이 무너져버리니 모든 코드들이 미쳐돌아가기 시작했습니다;;
예를 들어, insert를 할 때는 getCode를 통해 새로운 code를 받는데, getCode에서 새로운 코드를 생성하는 방법은 rs.last()로 이동하여, 마지막 행의 code를 받아온 뒤에 거기에 +1을 하여 새로운 code를 생성하는 방법입니다.
그러나 앞의 가정이 무너지면 더이상 마지막 행에 있는 code가 제일 큰 수가 아니기 때문에 이 방법을 사용할 수 없고, 몇 번째에 있는 code가 가장 큰 code인지 알기 어려워집니다ㅠ
이 뿐만 아니라 update와 delete메소드에서도 당연히 code는 입력 순서에 맞게 순차적으로 증가한다는 가정하에서 주소록의 배열 위치를 기준으로 반복을 돌리면서 rs.next 이용해 code를 찾았고, 이는 앞의 가정이 무너진다면 더이상 이용할 수 없는 logic입니다;;
대안책을 사용하고나니 앞의 가정이 무너져서 여러 메소드들들을 모두 새로운 로직을 짜서 변경해줘야하는 상황이 발생했습니다.
그래서 생각을 바꿔먹기로 했습니다;;
자기 합리화를 하기 시작했습니다.
“정렬을 시킨다는 것은 기존의 입력 순서를 내가 원하는 기준으로 바꿔버리겠다는 뜻이고, 입력 순서를 바꾼다는 의미는 code도 내가 원하는 기준으로 바꿔버린다는 뜻이다”라고 말이죠…
이게 맞는지는 모르지만 일단 이렇게 해석을 함으로써 replace는 save와 똑같은 로직을 가지게 되고, 메소드 이름은 바꾼다는 의미 그대로 replace가 되었습니다.
이렇게 길었던 데이터베이스 응용프로그래밍을 마무리 짓게 됩니다.
앞에서 구현한 자바입출력과 데이터베이스 차이점
앞에서 자바입출력으로 외부파일을 load/save를 구현했습니다.
save만 있다 보니 문제는 프로그램에서 load받은 내용을 가지고, 새로운 내용을 추가하거나, 변경하거나 삭제하다가 도중에 예기치 못한 상황으로 프로그램이 꺼지게 되면 프로그램에 변경된 사항들은 save되지 못한다는 점입니다.
즉, 정상적으로 프로그램이 종료될 때만 save되어 데이터가 보존되고, 프로그램이 갑자기 비정상적으로 꺼지게 되면 이때까지 내용이 저장되지 못하는, 실시간성이 없다는 점이었습니다.
이를 보완하기 위해 데이터베이스에서는 기재하기를 할 때는 바로 insert호출, 수정하기를 할 때는 바로 update호출, 지우기를 할 때는 바로 delete 호출을 통해 실시간으로 변경 내용을 반영하기 때문에 프로그램이 도중에 비정상적으로 꺼지더라도 변경사항을 보존할 수 있습니다.
그렇게 되면 실시간으로 내용이 반영되다보니 프로그램이 종료될 떄 save가 더이상 필요가 없기는 합니다만, 프로그래머가 프로그램을 작성하면서 실수로 해당 메소드 호출을 빼먹었거나, 작성 중에 테스트를 위해서 등등으로 작성해둘 필요는 있는 것 같습니다.
MySQL 연동 결과
비어있는 주소록에 “홍길동”을 기재하도록 하겠습니다.
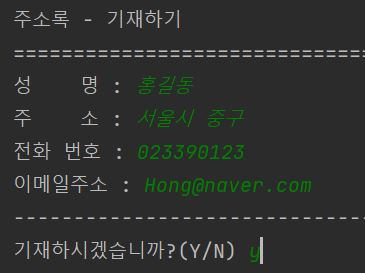
“홍길동”을 기재한 후에 MySQL 8.0 Command Line Client에 가서 전체 데이터 검색을 해보겠습니다.
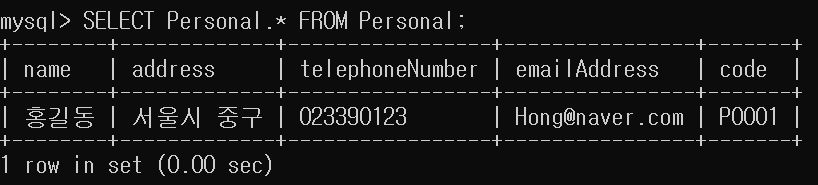
보시다시피 MySQL에 데이터가 잘 추가된 것을 볼 수 있습니다.
다음은 제가 C++과 MFC로 구현했던 프로그램인데 이 역시 MySQL에서 같은 addressBook데이터베이스를 이용하고 있습니다.
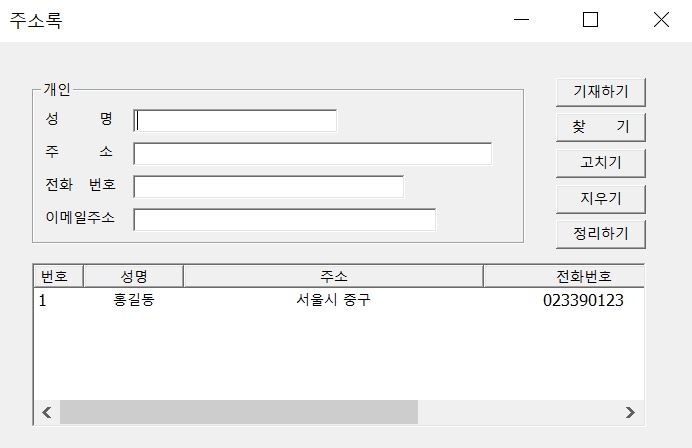
MFC로 프로그래밍된 주소록에서도 똑같은 데이터가 저장되어 있음을 확인할 수 있습니다.
이처럼 똑같은 데이터베이스를 사용하고 있으면 위와 같이 여러 프로그램에서 내용을 실시간으로 공유할 수 있습니다.
다음은 홍길동의 주소를 “서울시 중구”에서 “서울시 서초구”로 고쳐봤습니다.
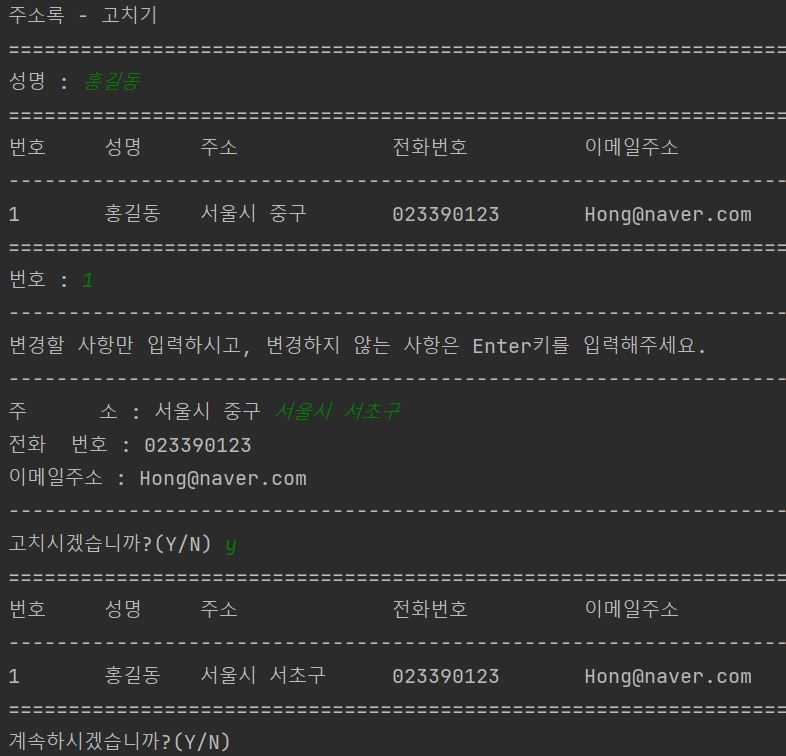
이 후 MySQL 8.0 Command Line Client과 MFC프로그래밍에서도 변경된 결과를 확인하실 수 있습니다.
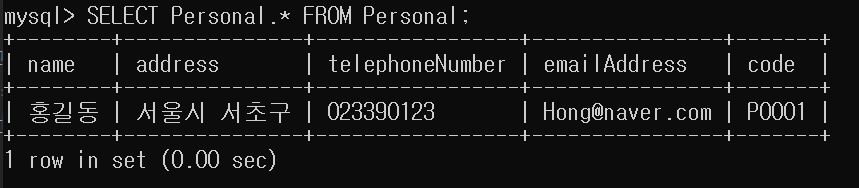
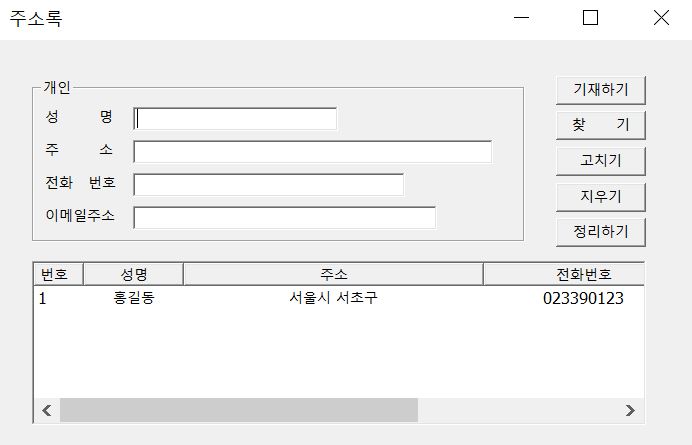
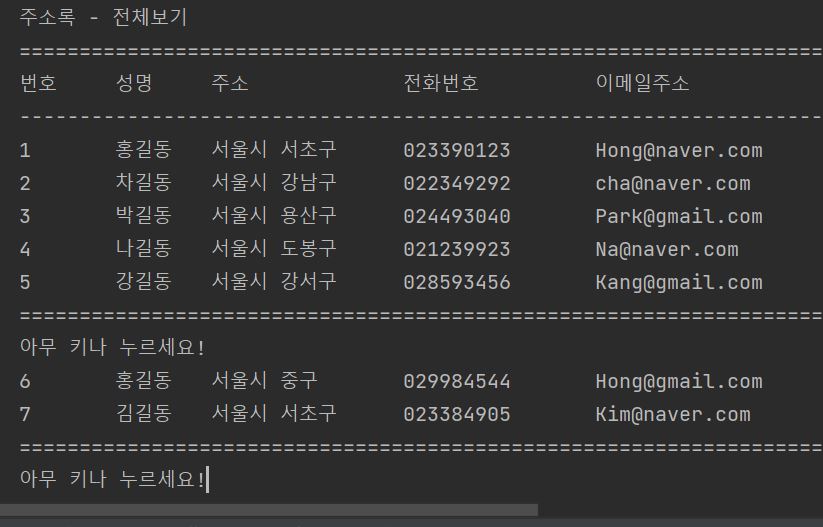
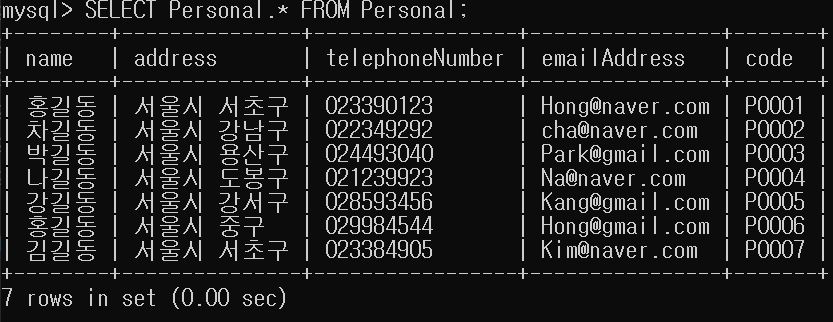
다음은 한꺼번에 여러 개인들을 입력한 후에 콘솔창에서 전체보기, MySQL 8.0 Command Line Client과 MFC프로그래밍에서도 전체보기를 해보도록 하겠습니다.
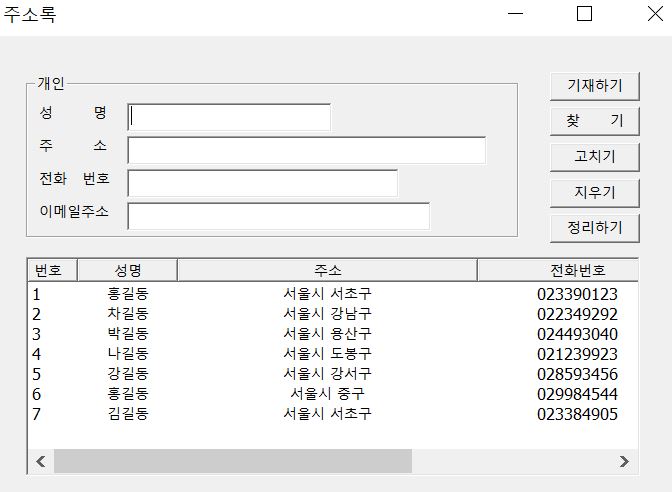
여기서 이제 정리하기를 하고 그 결과를 보도록 하겠습니다.
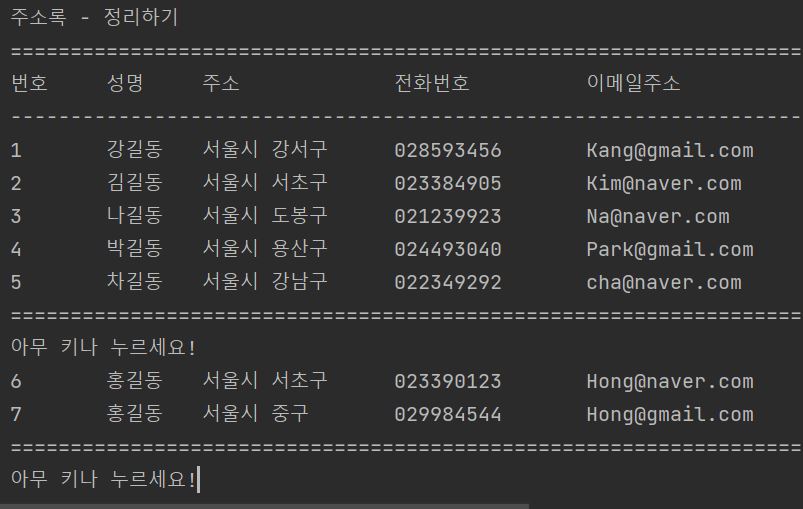
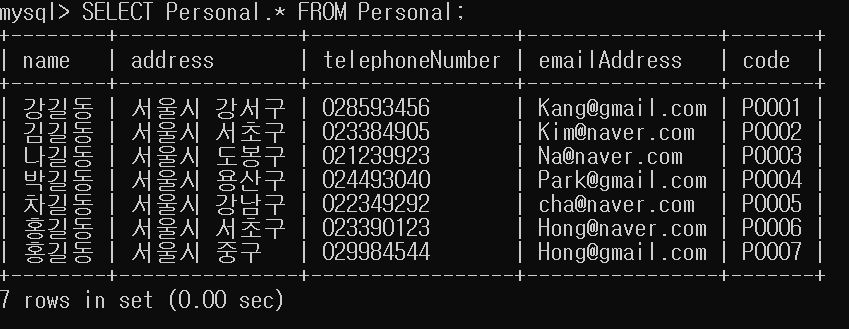
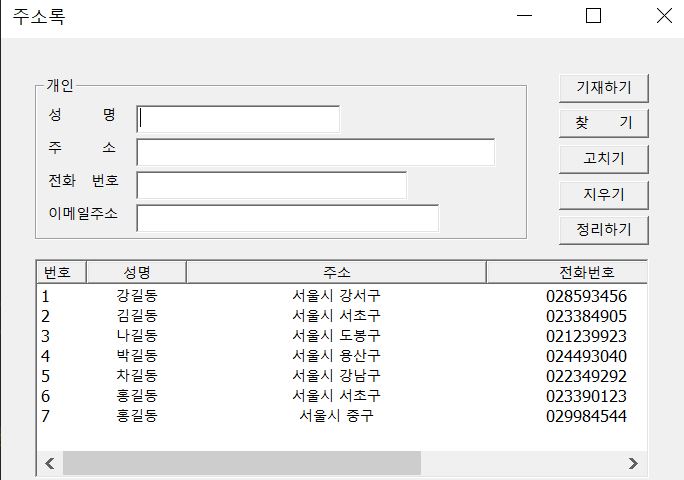
여기서 첫번째 홍길동(서울시 서초구, P0006)을 지워보도록 하겠습니다.
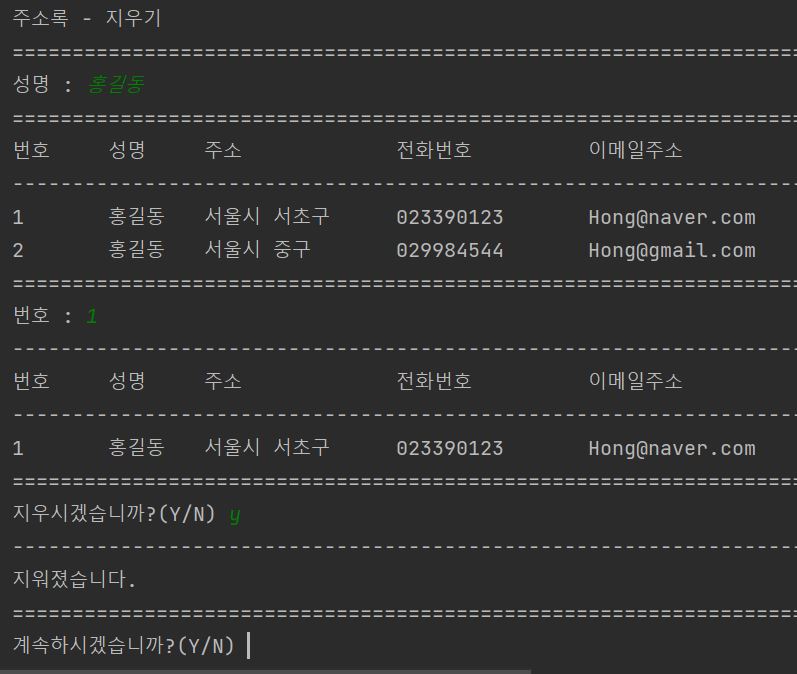
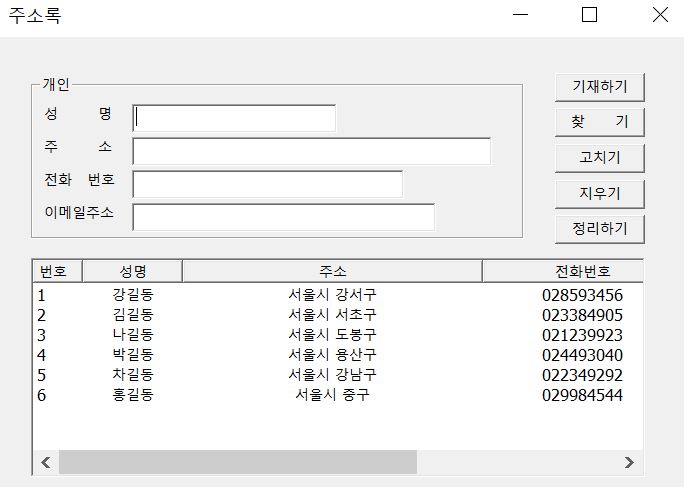
정리하기와 지우기 역시 모두 제대로 작동함을 알 수 있습니다.
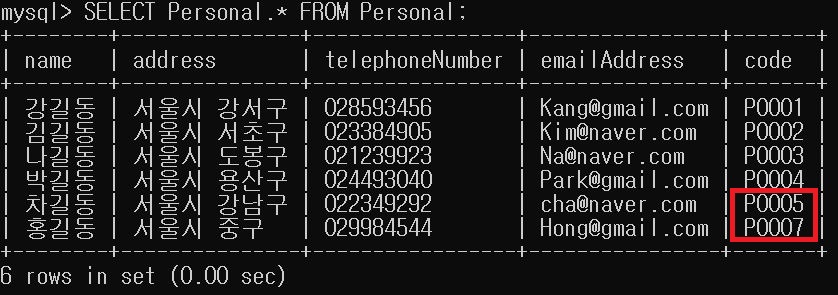
여기서 이제 데이터베이스에서 P0006번째 code를 가진 데이터가 지어지고, P0007번째 code를 가진 데이터는 데이터베이스에 남아있습니다.
여기서 새로운 데이터를 추가하면 P0008번째 코드를 가져야하는데 그것을 마지막으로 확인해보도록 하겠습니다.
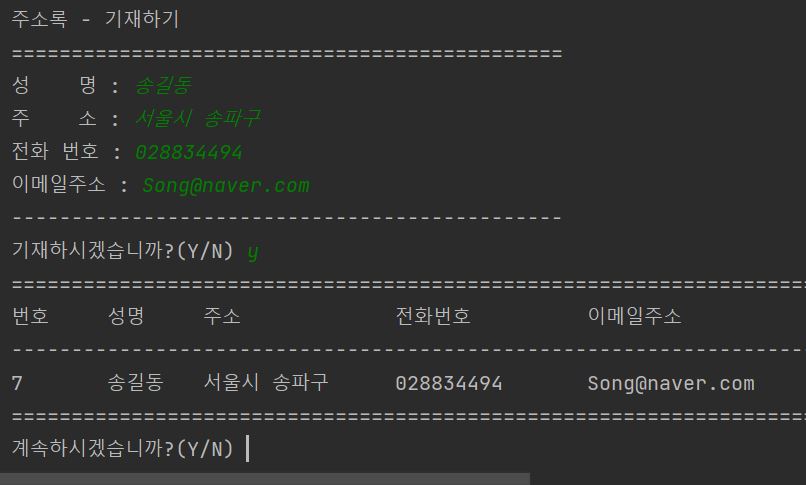
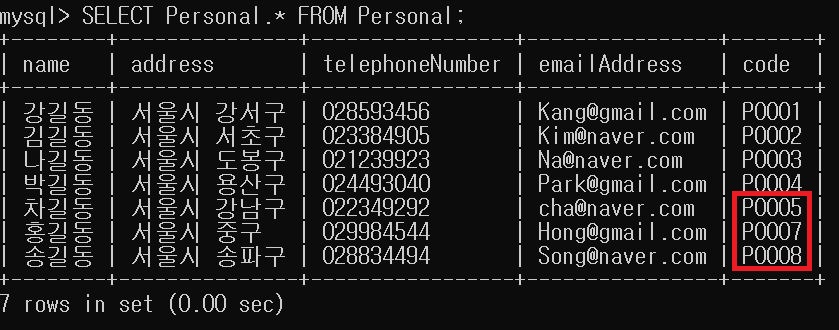
모두 다 잘 작동함을 확인할 수 있었습니다.
마치며
이상으로 “Java프로젝트하면서 데이터베이스 개념 적용 및 MySQL과 연동시키기”를 마치도록 하겠습니다.
이번 프로젝트를 진행하면서 데이터베이스의 기본 개념과 MySQL쿼리문의 문법, 그리고 Java와 데이터베이스 연동시 이용하는 클래스들과 그 메소드들에 대해 공부할 수 있었습니다.
긴 글을 읽어주셔서 감사합니다.
궁굼한 점이나 미흡한 사항 또는 틀린 점은 언제든지 댓글을 남겨주시거나 이메일을 보내주시면 확인 후에 답해드리도록 하겠습니다^^
다음에는 새로운 프로젝트를 진행하려고 합니다.
다음은 “Java프로젝트하면서 Object 메소드 오버라이딩 개념 익히기”를 작성하도록 하겠습니다.
댓글남기기